







































Robots.txt là gì? Cách tối ưu cho file Robots.txt
SEO không chỉ xoay quanh việc nghiên cứu từ khóa và xây dựng backlink. Thứ hạng tìm kiếm của bạn còn chịu ảnh hưởng bởi một hoạt động khác có liên quan đến khía cạnh kỹ thuật gọi là Technical SEO.
Và trong hoạt động này, file robots.txt sẽ trở thành một yếu tố quan trọng có tác động đến thứ hạng. Hãy cùng Đào tạo SEO Á Âu tìm hiểu về cách tối ưu cho tập tin này nhé!

Tệp robots.txt là gì?
Khi bot của search engine truy cập và thu thập dữ liệu của một website, nó sẽ sử dụng file robots.txt để xác định xem những phần nào của trang cần được lập chỉ mục (index).
Các sơ đồ website (sitemap) được lưu trữ trong thư mục gốc (root folder) của bạn và trong tập tin robots.txt. Việc tạo ra một sơ đồng trang web là để cho các máy tìm kiếm có thể phát hiện và index nội dung của bạn dễ dàng hơn.
(Nguồn: Internet)
Hãy xem file robots.txt cũng giống như một bản “hướng dẫn sử dụng” cho các bot. Đó là hướng dẫn có các quy tắc mà robot của máy tìm kiếm cần tuân theo. Các quy tắc này sẽ báo cho các crawler biết những gì mà chúng được phép xem (như những page nằm trên sitemap của bạn) và những phần nào của website bị hạn chế.
Nếu file robots.txt của bạn không được tối ưu hóa đúng cách, nó có thể gây ra những vấn đề SEO lớn cho website. Đó là lý do tại sao quan trọng là bạn cần hiểu được chính xác file này sẽ hoạt động như thế nào và những gì bạn cần thực hiện để đảm bảo rằng các thành phần về mặt kỹ thuật này đang tạo ra sức mạnh, thay vì “gây hại” cho bạn.
Tóm tắt lại định nghĩa về file robots.txt, theo Google thì:
“File robots.txt cho các crawler của search engine biết các trang nào từ website của bạn mà chúng có thể hoặc không thể yêu cầu. File này chủ yếu dùng để hạn chế tình trạng crawler gửi quá nhiều yêu cầu đến trang web và làm cho trang bị quá tải; nhưng nó không phải là một cơ chế để ngăn một trang không xuất hiện trên Google. Nếu muốn làm như thế, bạn nên sử dụng lệnh noindex hoặc bảo vệ trang của mình bằng mật khẩu.”
Tệp robots.txt dùng cho mục đích gì?
File robots.txt được sử dụng chủ yếu để quản lý truy cập của các crawler đến website của bạn, và thường để “chặn” một trang khỏi Google, tùy thuộc vào loại file là gì:
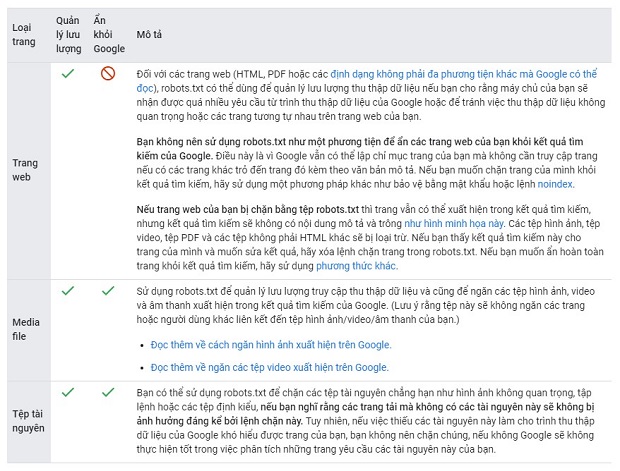
(Nguồn: Google Support)
Tìm file robots.txt ở đâu?
Trước khi thực hiện những thao tác sâu hơn, bước đầu tiên chúng ta cần kiểm tra xem mình đã có một file robots.txt chưa. Nhiều người có thể chưa từng truy cập vào đây bao giờ.
Cách dễ dàng nhất để xem website của bạn đã có file robots.txt này chưa chính là nhập địa chỉ URL của website vào một trình duyệt web, gắn thêm đoạn “/robots.txt” như hình dưới đây:
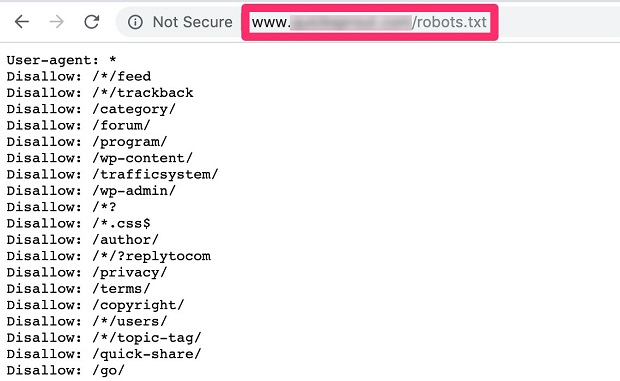
(Nguồn: Internet)
Sẽ có 3 trường hợp có thể xảy ra:
- Bạn sẽ nhìn thấy một file robots.txt giống như hình ở trên (nếu bạn chưa dành thời gian để tối ưu hóa cho nó thì có thể nó sẽ không được chi tiết như vậy).
- Bạn sẽ thấy một file robots.txt hoàn toàn trống, nhưng ít nhất thì nó cũng được thiết lập bởi các lệnh.
- Bạn sẽ nhận được thông báo lỗi 404 vì trang đó không tồn tại.
Hầu hết chúng ta đều sẽ rơi vào 2 trường hợp đầu tiên. Bạn sẽ hiếm khi gặp lỗi 404 bởi vì phần lớn website mặc định đều có một file robots.txt khi website được tạo ra. Các thiết lập mặc định này vẫn sẽ được giữ nguyên nếu bạn không thực hiện thay đổi nào.
Để tạo hoặc chỉnh sửa file này, bạn chỉ cần điều hướng đến thư mục gốc (root folder) của website của bạn.
Điều chỉnh nội dung file robots.txt
Thông thường thì bạn sẽ không muốn thay đổi quá nhiều với tập tin này vì đây không phải là yếu tố bạn cần cập nhật thường xuyên,
Lý do duy nhất tại sao bạn cần bổ sung thêm vào file robots.txt đó là khi có những page cụ thể nào đó trên website mà bạn không muốn các bot thu thập dữ liệu và index. Để thao tác, bạn cần làm quen với cú pháp được sử dụng cho các lệnh trong file. Dưới đây là cú pháp được sử dụng phổ biến nhất.
Đầu tiên, bạn cần xác định các crawler. Trong đây, nó được đề cập đến bằng tên gọi “User-agent”.
User-agent: *
Cú pháp này dùng để chỉ tất cả crawler của toàn bộ công cụ tìm kiếm (Google, Yahoo, Bing…)
User-agent: Googlebot
Như tên gọi của nó, thì giá trị này dùng để tham chiếu trực tiếp đến các crawler của Google.
Sau khi đã xác định crawler, bạn có thể chọn lệnh “allow” (cho phép thu thập dữ liệu) hoặc “disallow” (không cho phép thu thập dữ liệu) các content trên website của mình. Chẳng hạn như ví dụ này:
User-agent: *
Disallow: /wp-content/
Trang này được sử dụng để hỗ trợ quản lý nền tảng backend trong WordPress, nên câu lệnh ở trên là để thông báo cho toàn bộ crawler (User-agent: *) không thu thập dữ liệu của trang đó. Không có lý do gì mà các bot lại phải lãng phí thời gian quét và thu thập các trang này cả.
Giả sử nếu bạn muốn báo cho toàn bộ các bot không thu thập dữ liệu của một trang trên website có địa chỉ URL là: http://www.website.com/samplepage1/ thì cú pháp sẽ giống như thế này:
User-agent: *
Disallow: /samplepage1/
Dưới đây là một ví dụ khác:
Disallow: /*.gif$
Câu lệnh “Disallow” này sẽ “chặn” crawler thu thập dữ liệu của một loại file cụ thể, trong trường hợp này là .gif (ảnh động). Bạn có thể tham khảo thêm bảng đối chiếu dưới đây từ Google để biết thêm các quy tắc và ví dụ phổ biến:
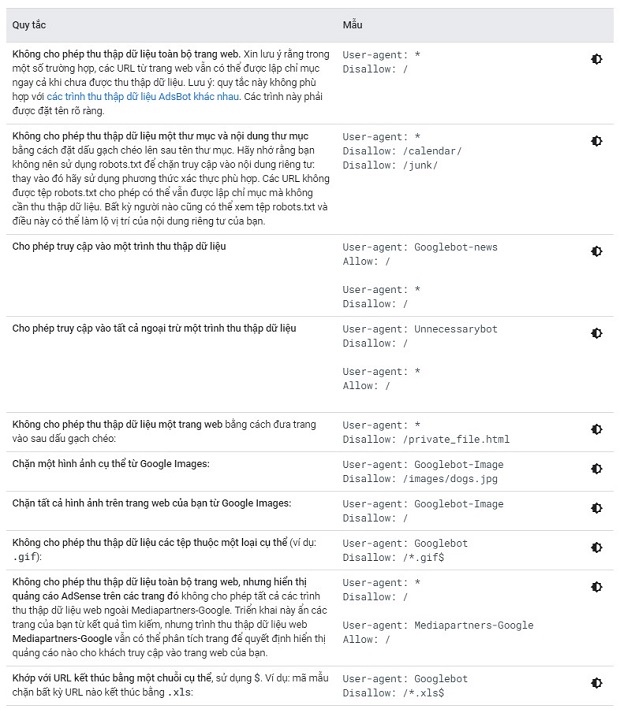
(Nguồn: Google Support)
Nếu bạn muốn “chặn” các trang, các file hoặc nội dung trên website không bị toàn bộ các crawler (hoặc một số crawler cụ thể) thu thập dữ liệu, bạn chỉ cần tìm cú pháp câu lệnh thích hợp và chỉnh sửa nó trong một trình soạn thảo văn bản, sau khi đã hoàn thành các câu lệnh, hãy copy và dán chúng vào file robots.txt.
Tại sao cần tối ưu file robots.txt
Bạn cần hiểu được điều này: Mục đích của file robots.txt không phải là để chặn hoàn toàn các trang hoặc nội dung website không bị thu thập bởi công cụ tìm kiếm.
Thay vào đó, chúng ta chỉ đang cố gắng tối ưu hóa tính hiệu quả cho crawl budget của các bọ quét (crawl budget hay ngân sách thu thập dữ liệu là số lần mà các crawler truy cập website của bạn trong một khoảng thời gian nhất định). Những gì bạn đang làm là thông báo cho các bot rằng chúng không cần quét qua và thu thập dữ liệu từ các trang không cần thiết.
Dưới đây là một phần tóm lượt về cơ chế hoạt động của crawl budget. Nó sẽ được chia làm 2 phần:
- Crawl rate limit
- Crawl demand
Bạn có thể tìm hiểu thêm chi tiết về 2 thành phần này tại đây:
https://www.seroundtable.com/google-crawl-budget-23265.html
“Crawl rate limit” thể hiện số lượng kết nối song song mà một crawler có thể thực hiện đến một website nào đó. Chỉ số này cũng bao gồm thời gian giữa các lần tìm nạp (time between fetches).
Các website phản hồi nhanh chóng đều có “crawl rate limit” cao hơn, nghĩa là chúng sẽ có nhiều kết nối với các bot hơn. Ngược lại, những website bị chậm lại do quá trình thu thập sẽ không được thu thập dữ liệu thường xuyên.
Các website cũng được quét và thu thập dữ liệu dựa trên nhu cầu (demand). Điều này đồng nghĩa với việc các website nổi tiếng được thu thập dữ liệu với tần suất nhiều hơn. Trong khi các website không phổ biến hoặc cũ kĩ hay không được cập nhật thường xuyên sẽ không thường được thu thập dữ liệu, ngay cả khi vẫn chưa đạt tới giới hạn về “crawl rate limit”.
Bằng cách tối ưu hóa file robots.txt, bạn đang làm cho công việc của các crawler trở nên dễ dàng hơn. Theo Google, có một số ví dụ về các yếu tố làm ảnh hưởng đến crawl budget:
- Session ID (là một dãy số độc nhất mà server của website gán cho một người dùng trong phiên truy cập của người dùng đó).
- Điều hướng đa chiều (faceted navigation, là một tính năng phổ biến trên các website thương mại điện tử nơi sản phẩm có thể được lọc theo nhiều tiêu chí khác nhau)
- Các trang báo lỗi (error pages)
- Các trang đã bị hack
- Nội dung trùng lặp (duplicate content)
- Các vấn đề về “infinite spaces” và (khi một website tạo ra một danh sách gần như bất tận các địa chỉ URL mà Google có thể “mắc kẹt” và cố gắng thu thập dữ liệu của toàn bộ các trang này) và vòng lặp proxy vô hạn “infinite proxies”
- Nội dung có chất lượng thấp (low-quality content)
- Spam
Bằng cách sử dụng file robots.txt để “disallow” những loại content này khỏi bị các crawl thu thập dữ liệu, chúng ta sẽ giúp chúng có nhiều thời gian hơn để khám phá và index những content quan trọng trên website của bạn.
Dưới đây là một ví dụ minh họa về các website có và không có tối ưu hóa cho file robots.txt:
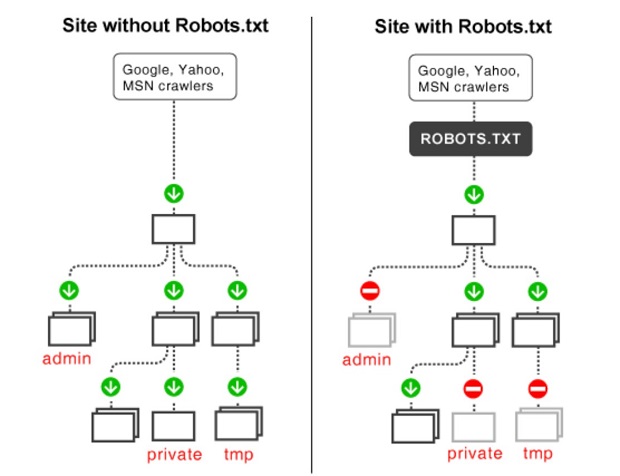
(Nguồn: Internet)
Crawler của công cụ tìm kiếm sẽ phải mất nhiều thời gian hơn, đồng nghĩa với việc mất nhiều “crawl budget” hơn (đối với website bên trái). Nhưng website bên phải sẽ đảm bảo rằng chỉ những nội dung “xứng đáng” mới được thu thập dữ liệu mà thôi.
Ngoài ra, dưới đây là một trường hợp khác mà bạn có thể tận dụng sức mạnh của file robots.txt.
Có thể tất cả chúng ta đều biết rằng những nội dung trùng lặp (duplicate content) không tốt cho SEO. Nhưng có những lúc website của chúng ta cần có các nội dung như thế. Chẳng hạn, chúng ta có thể tạo ra những phiên bản phục vụ cho việc in ấn dễ dàng hơn của một số page cụ thể. Đó được xem là duplicate content. Do đó, chúng ta có thể báo cho các bot biết là không thu thập dữ liệu của các trang này bằng cách tối ưu cho file robots.txt.
Kiểm tra file robots.txt
Khi bạn đã tìm, điều chỉnh và tối ưu hóa cho file robots.txt, đã đến lúc kiểm tra xem mọi thứ có hoạt động hiệu quả hay không.
Đầu tiên, bạn cần đăng nhập vào tài khoản Google Search Console. Sau đó điều hướng đến mục “Crawl” từ giao diện quản lý chính.
(Nguồn: Internet)
Nhấp vào đó, và chọn “robots.txt Tester”.
(Nguồn: Internet)
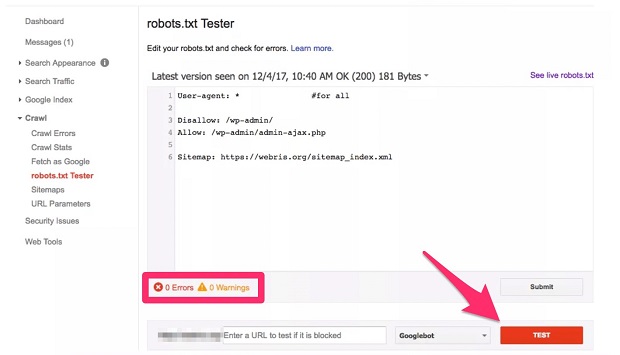
Nhấp vào nút “Test” màu đỏ ở góc phải bên dưới màn hình.
(Nguồn: Internet)
Nếu có vấn đề, bạn sẽ thấy xuất hiện lỗi ở mục “Errors” và “Warnings” bạn có thể chỉnh sửa trực tiếp cấu trúc lệnh trong trình kiểm tra này. Tiếp tục chạy kiểm tra như thế cho đến khi mọi thứ đều mượt mà.
Có một lưu ý quan trọng, đó là các thay đổi được thực hiện trong trình kiểm tra này không được lưu lại vào website của bạn. Nên chúng ta cần phải đảm bảo rằng mình đã copy và dán những nội dung thay đổi này vào trong file robots.txt thực sự.
Ngoài ra, công cụ này chỉ dùng để kiểm tra đối với các bot và crawler của Google. Nó không có khả năng dự đoán xem những công cụ tìm kiếm khác sẽ đọc file robots.txt của bạn ra sao. Tuy nhiên, xét đến việc Google chiếm đến 89,95% thị phần của hoạt động tìm kiếm trên toàn cầu, thì có lẽ như chúng ta cũng chưa cần sử dụng thêm những công cụ thử nghiệm khác.
Những phương pháp tốt nhất để tối ưu cho file robots.txt
Tập tin robots.txt của bạn cần được đặt tên là “robots.txt” nếu muốn được tìm thấy. Những trường hợp viết ký tự in hoa như “Robots.txt” hay “robots.TXT” đều sẽ không được chấp nhận. Bên cạnh đó, file robots.txt phải luôn được đặt trong thư mục gốc (root folder) của website trong thư mục cấp cao nhất (top-level directory) của host.
Bất kỳ ai cũng có thể xem file robots.txt của bạn. Họ chỉ cần nhập địa chỉ URL của website cùng với hậu tố “/robots.txt” sau tên miền gốc để xem nó.
Trong hầu hết trường hợp, thì chúng ta không nên thiết lập các quy tắc riêng cho các crawler của các công cụ tìm kiếm khác nhau. Vì việc này không có nhiều ý nghĩa. Thay vào đó, bạn nên tạo ra các quy tắc có thể áp dụng cho toàn bộ user-agent.
Việc sử dụng cú pháp “disallow” trong file robots.txt sẽ không làm cho một page không được index. Thay vào đó nếu muốn, bạn cần phải sử dụng thẻ “noindex”.
Crawler của các công cụ tìm kiếm cực kỳ tiên tiến. Về cơ bản thì chúng sẽ xem qua nội dung trên website của bạn cũng giống với cách mà một người xem trang. Vậy nên nếu website của bạn sử dụng CSS và JS để hoạt động, bạn không nên “chặn” những thư mục này trong file robots.txt của mình.
Nếu bạn muốn file robots.txt có thể được ghi nhận ngay lập tức sau khi nó được cập nhật, hãy gửi nó trực tiếp vào Google Search Console, thay vì đợi website của mình được thu thập dữ liệu lần nữa.
Link equity hay link juice (sức mạnh truyền đi qua các đường link) không thể đường truyền đi từ các trang bị chặn đến các trang đích. Điều này đồng nghĩa với việc các liên kết trên các trang bị “disallow” sẽ được xem là “nofollow”. Vậy nên một số link sẽ không được index trừ khi chúng nằm trên các trang khác có thể được truy cập bởi các công cụ tìm kiếm.
File robots.txt không phải là một biện pháp thay thế để chặn các thông tin riêng tư của người dùng và những thông tin “nhạy cảm” khác xuất hiện trên SERP. Và lưu ý là, các page bị “disallow” vẫn có thể được index. Nên nếu muốn “chặn” các trang này hoàn toàn, bạn cần đảm bảo rằng những trang đó được bảo vệ bằng mật khẩu (password-protected) và sử dụng lệnh noindex. Và các sitemap nên được đặt ở cuối cùng của file robots.txt.
Kết luận
Qua bài viết này, HNAAu hi vọng có thể mang đến cho bạn những kiến thức tổng quan nhất về file robots.txt. Hãy nhớ rằng đây không phải là một tập tin mà chúng ta sẽ chỉnh sửa quá thường xuyên. Và hãy cực kỳ cẩn thận, kiểm tra mọi thứ thật kỹ càng trước khi lưu lại các thay đổi trong nội dung của file. Một lỗi cũng có thể làm cho công cụ tìm kiếm ngưng thu thập dữ liệu website của bạn hoàn toàn và gây ảnh hưởng lớn đến thứ hạng SEO. Do vậy, bạn chỉ nên thực hiện các thay đổi khi thực sự cần thiết.
Nếu được tối ưu hóa đúng cách, website của bạn sẽ được thu thập dữ liệu một cách hiệu quả thông qua crawl budget của Google. Điều này sẽ làm tăng khả năng những nội dung hàng đầu của bạn sẽ được nhìn thấy, index và xếp hạng.




ĐƠN VỊ TUYỂN DỤNG CHEFJOB.VN
ĐẦU BẾP - BẾP BÁNH - PHA CHẾ - PHỤC VỤ - BUỒNG PHÒNG
LỄ TÂN - QUẢN LÝ NHÀ HÀNG - KHÁCH SẠN
Hotline: 1900 2175 - Web: www.chefjob.vn
SIÊU THỊ ĐVP MARKET
Chuyên bán sỉ lẻ Nguyên liệu - Dụng cụ - Máy móc
TRÀ SỮA - CAFÉ - QUÁN ĂN - QUÁN KEM - KINH DOANH BÁNH
Hotline: 028 7300 1770 - Web: www.dvpmarket.com
Ý kiến của bạn