







































Deindex là gì? Cách deindex để tăng nhanh lượng truy cập tự nhiên (Phần 2)
Tiếp nối phần 1 của bài viết về chủ đề Deindex lần trước, phần 2 hôm nay sẽ tiếp tục trình bày những cách deindex hiệu quả, bao gồm việc sử dụng các thẻ noindex/nofollow và các kỹ thuật liên quan đến file robots.txt. Hãy cùng Khóa học SEO Á Âu khám phá nhé!
Cách đặt thẻ “noindex” và “nofollow” cho trang
Đầu tiên, bạn cần copy đoạn mã của thẻ mà mình muốn sử dụng:
Thẻ noindex
<META NAME=”robots” CONTENT=”noindex”>
Thẻ nofollow
<META NAME=”robots” CONTENT=”nofollow”>
Kết hợp cả hai
<META NAME=”robots” CONTENT=”noindex,nofollow”>
Việc thêm các thẻ này vào rất đơn giản, chỉ cần chèn chúng vào khu vực header trong mã HTML của trang. Mở mã nguồn (source code) của web page mà bạn muốn deindex. Sau đó, dán đoạn mã vào một dòng mới bên dưới phần <head>.
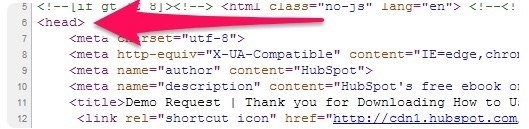
(Nguồn ảnh: Internet)
Sau khi chèn xong thì kết quả sẽ giống với hình dưới đây.
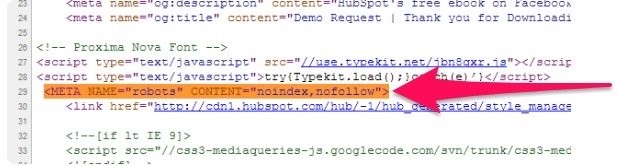
(Nguồn ảnh: Internet)
Hãy nhớ là thẻ </head> là dấu hiệu kết thúc của phần header. Không được đặt thẻ noindex hoặc nofollow bên ngoài khu vực này. Sau đó, hãy lưu lại những thay đổi và bạn đã hoàn tất. Giờ đây máy tìm kiếm sẽ bỏ trang của bạn ra khỏi các kết quả tìm kiếm.
Ngoài ra, bạn có thể thông báo với máy tìm kiếm không quét qua một danh sách các trang cụ thể bằng cách điều chỉnh file robots.txt.
Robots.txt là gì và cách truy cập
Robots.txt là một tệp văn bản mà các nhà quản trị website có thể tạo ra để thông báo một cách chính xác cho các robot của máy tìm kiếm biết về cách mà họ muốn các trang của mình được quét qua hoặc các đường link được lần theo như thế nào.

(Nguồn ảnh: Internet)
Các file robots.txt cho biết rằng liệu một phần mềm thu thập dữ liệu website cụ thể có được phép thu thập dữ liệu đối với những phần nhất định của một website hay không.
Nếu bạn muốn “nofollow” nhiều web page cùng một lúc, bạn có thể làm việc đó bằng cách truy cập vào file robots.text của website.
Đầu tiên, cần kiểm tra xem website của bạn đã có file robots.txt hay chưa. Hãy nhập vào địa chỉ: www.websitecủabạn.com/robots.txt. Dưới đây là ví dụ minh họa:
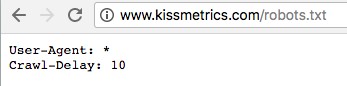
(Nguồn ảnh: Internet)
Trong hình ảnh trên, bạn có thể thấy dòng “Crawl-delay: 10”, đây là dòng lệnh đưuọc thêm vào website để hạn chế việc các bot của máy tìm kiếm thu thập dữ liệu từ website của bạn quá thường xuyên. Việc này sẽ giúp ngăn chặn tình trạng các máy chủ bị quá tải.
Nếu bạn gõ vào địa chỉ trên mà không có gì xuất hiện, thì website của bạn vẫn chưa có file robots.txt, như trang của Disney trong hình bên dưới (thay vì một trang trống thì thỉnh thoảng bạn cũng có thể thấy hiển thị lỗi 404).
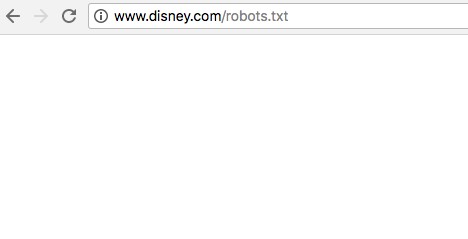
(Nguồn ảnh: Internet)
Bạn có thể dễ dàng tạo một file robots.txt bằng bất kỳ trình soạn thỏa văn bản nào. Cấu trúc tổng thể của một file robots.txt sẽ bao gồm hai mục:
User-agent: *
Disallow: /
Sau đó bạn có thể thêm vào phần đuôi của những địa chỉ URL (ending URL) của tất cả các trang mà bạn không muốn Googlebot thu thập dữ liệu.

(Nguồn ảnh: Internet)
Sau đây là một số đoạn mã hữu dụng cho robots.txt mà bạn có thể sử dụng:
| Cho phép index mọi thứ có trên website | User-agent: * Disallow: hoặc User-agent: * Allow: / |
| Không cho phép index | User-agent: * Disallow: / |
| Deindex một thư mục cụ thể | User-agent: * Disallow: /folder/ |
| Không cho phép Googlebot index một thư mục, ngoại trừ một file cụ thể có trong thư mục đó | User-agent: Googlebot Disallow: /folder1/ Allow: /folder1/myfile.html |
| Chặn truy cập đến các địa chỉ URL có chứa một ký tự đặc biệt nào đó, như là một dấu chấm hỏi (?) | User-agent: * Disallow: /*? |
| Chèn noindex từ file robots.txt | User-agent: Googlebot Disallow: /page-uno/ Noindex: /page-uno/ |
Bên cạnh đó, Google và Bing cũng cho phép người dùng sử dụng các ký tự đại diện (wildcard, là các ký tự đại diện để thay thế cho một chuỗi ký tự nào đó, chẳng hạn như dấu *…) trong các file robots.txt.
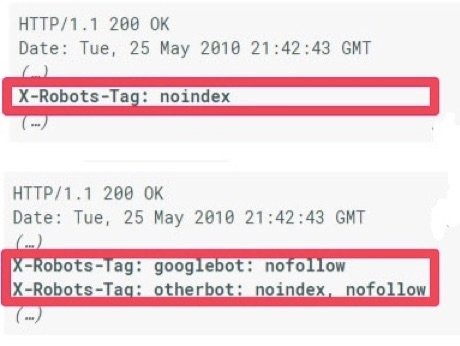
Ngoài ra, bạn cũng có thể thay thế bằng cách sử dụng thẻ X-Robots-tag. Thẻ X-Robots-Tag là bất kỳ lệnh nào dùng trong một HTTP header – là phần tiêu đề của giao thức HTTP phản hồi lại yêu cầu, được gửi về từ máy chủ website. Không giống như các thẻ meta robots, X-Robots-Tag không nằm trong mã HTML của một trang.
Dưới đây là ví dụ về thẻ X-Robots-tag không thu thập dữ liệu (“no crawl”):
HTTP/1.1 200 OK
(…)
X-Robots-Tag: noindex
(…)
(Nguồn ảnh: Internet)
Sẽ có một số trường hợp bạn đã chèn các thẻ nofollow và/hoặc thẻ noindex hoặc thay đổi file robots.txt, nhưng một số trang vẫn xuất hiện trên SERPs. Đây là một điều bình thường và bây giờ hãy cùng tìm hiểu cách khắc phục tình trạng này nhé.
Tại sao các trang vẫn xuất hiện trên SERPs (trong thời gian đầu)?
Nếu các trang của bạn vẫn xuất hiện trong các kết quả tìm kiếm, có khả năng là vì Google vẫn chưa quét lại website của bạn từ khi bạn thêm những thẻ đó vào.
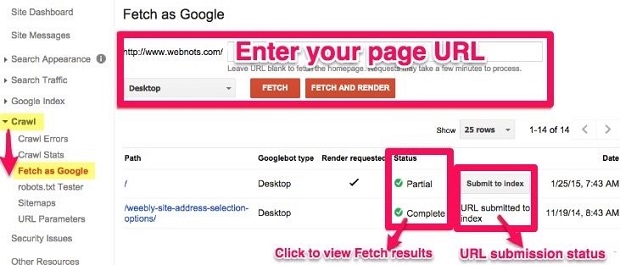
Hãy yêu cầu Google thu thập lại dữ liệu website một lần nữa bằng cách sử dụng công cụ Fetch as Google. Chỉ cần nhập vào địa chỉ URL của trang, nhấp vào để xem các kết quả, và kiểm tra trạng thái của URL.
(Nguồn ảnh: Internet)
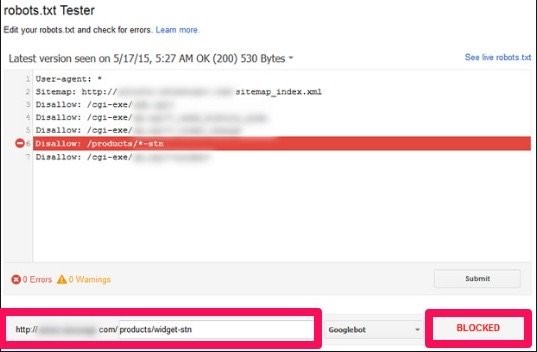
Một lý do khác nữa là vì file robots.txt của bạn có thể có một số lỗi. Bạn có thể chỉnh sửa hoặc kiểm tra file robots.text của mình bằng công cụ robots.txt Tester. Giao diện của nó sẽ giống như hình dưới đây:
(Nguồn ảnh: Internet)
Không dùng đồng thời thẻ meta noindex và thẻ disallow trong robots.txt
Khi bạn đặt thẻ meta noindex cho một loạt trang nhưng vẫn sử dụng thẻ disallow đối với những trang này trong file robots.txt, thì các bot sẽ bỏ qua thẻ noindex của bạn (bởi vì khi đó thì trang đã bị chặn). Vậy nên, đừng sử dụng hai thẻ này cùng một lúc.
Ngoài ra, Google sẽ tiến hành deindex một trang đã được index chỉ khi hệ thống quét và thu thập lại dữ liệu (re-crawl) trên trang, bạn nên giữ nguyên sitemap trong một khoảng thời gian để các bọ quét có thể nhận biết được sự thay đổi này nhanh hơn. Khi Moz deindex các trang profile cộng đồng của họ, thì họ vẫn giữ nguyên bản đồ trang của các profile cộng đồng trong một vài tuần. Bạn cũng nên làm như thế.
Ngoài ra còn có một lựa chọn khác để ngăn website của bạn không bị thu thập dữ liệu mà vẫn cho phép Google AdSense hoạt động được trên các trang.
Hãy nghĩ về một trong những trang của bạn, chẳng hạn như trang liên hệ (Contact Us) hoặc thậm chí là trang chính sách bảo mật (Privacy Policy). Có khả năng là chúng đều được trỏ đến từ mọi trang trên website thông qua menu chính hoặc menu ở chân trang (footer menu).
(Nguồn ảnh: Internet)
Sẽ có rất nhiều link equity (hay còn gọi là link juice, thuật ngữ dùng để chỉ sức mạnh của đường link) “chảy” đến những trang này. Bạn không muốn chúng bị lãng phí. Đặc biệt là khi nó truyền đi từ menu chính của bạn hoặc menu nằm ở dưới chân trang.
Và vì như vậy, bạn cần…
Không đưa những trang đã chặn trong robots.txt vào XML Sitemap của website
Nếu bạn chặn một trang trong file robots.txt nhưng sau đó lại đưa nó vào trong XML Sitemap, thì bạn đang “trêu chọc” Google. Trong khi Sitemap nói cho Google biết rằng một trang cần được index thì file robots.txt lại bỏ trang đó ra.
Bạn nên phân loại tất cả nội dung trên website của mình thành hai nhóm khác nhau:
1. Các trang có chất lượng cao có thể truy cập được thông qua tìm kiếm
2. Các trang utility page hữu ích cho người dùng (là những trang thường được đặt liên kết ở trên đầu của một website, chẳng hạn như “Home”, “About Us”, “Privacy Policy”…) nhưng không cần phải truy cập được thông qua tìm kiếm
Không có lý do gì cần phải chặn các nội dung ở nhóm 1 trong file robots.txt cả. Các nội dung này không nên để thẻ noindex. Hãy đưa tất cả những trang đó vào trong XML Sitemap của website.
Bạn nên chặn toàn bộ nội dung trong nhóm thứ hai bằng một thẻ noindex, nofollow hoặc bằng file robots.txt. Bạn không nên đưa những nội dung này vào trong bản đồ trang của mình.
Google sẽ sử dụng tất cả những gì bạn đưa vào XML Sitemap để hiểu về những gì nên được xem là quan trọng trên website của bạn. Nhưng chỉ vì Sitemap của bạn không có một trang nào đó, thì không có nghĩa là Google sẽ hoàn toàn bỏ qua nó. Hãy thực hiện tìm kiếm với toán tử “site:” để xem tất cả những trang mà Google hiện đang lập chỉ mục từ website của bạn và tìm xem có trang nào mà bạn có thể đã bỏ qua hoặc quên mất hay không.
Các trang yếu nhất mà Google vẫn đang index sẽ được liệt kê cuối cùng trong tìm kiếm với toán tử “site:”. Bạn cũng có thể dễ dàng xem được số lượng các trang đã nộp và được lập chỉ mục trong công cụ Google Webmaster Tools.
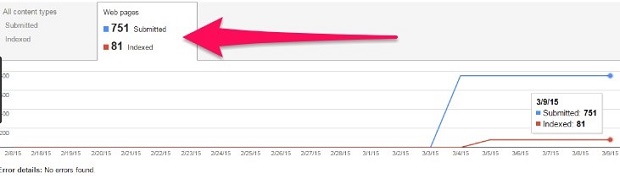
(Nguồn ảnh: Internet)
Tổng kết
Phần lớn mọi người đều quan tâm đến việc index cho các trang của mình, thay vì deindex chúng. Nhưng việc index quá nhiều trang không phù hợp thực sự có thể gây hại đến thứ hạng tổng thể của bạn.
1. Đầu tiên, bạn cần hiểu được sự khác nhau giữa hai khái niệm “crawling” và “indexing”. Crawling là hoạt động các bot quét và thu thập dữ liệu từ tất cả các đường link có trên mọi web page của một website. Còn indexing là hoạt động đưa một trang nào đó vào danh sách index (lập chỉ mục) bao gồm tất cả các trang có thể xuất hiện trên SERPs của Google.
2. Việc loại bỏ đi các trang không cần thiết khỏi SERPs, chẳng hạn như các trang cảm ơn có thể thúc đẩy lượng truy cập bởi vì Google sẽ chỉ tập trung vào việc xếp hạng những trang xứng đáng nhất, thay vì những trang không quan trọng.
Bên cạnh đó, hãy deindex những trang profile cộng đồng spam và không đủ tiêu chuẩn. Moz đã deindex những profile có ít hơn 200 điểm và điều đó đã giúp gia tăng lượng truy cập nhanh chóng.
3. Tiếp theo, bạn phải hiểu được sự khác nhau giữa thẻ noindex và nofollow.
Các thẻ noindex giúp loại bỏ các trang khỏi danh sách những trang có thể được tìm thấy của Google. Còn thẻ nofollow sẽ ngăn Google thu thập dữ liệu từ những đường link có trên trang. Hai thẻ này có thể được sử dụng riêng lẻ hoặc cùng nhau. Bạn chỉ cần thêm đoạn mã của các thẻ này vào khu vực header của mã HTML.
4. Bạn cũng cần hiểu về cách thức hoạt động của file robots.txt. Bạn có thể sử dụng tệp này để chặn Google thu thập dữ liệu của nhiều trang cùng một lúc.
5. Thời gian đầu thì các trang của bạn có thể vẫn còn xuất hiện trên SERPs, hãy sử dụng công cụ Fetch as Google để khắc phục vấn đề này.
6. Hãy nhớ là không bao giờ áp dụng thẻ noindex cho một trang và vẫn disallow trang đó trong file robots.txt. Ngoài ra, đừng bao giờ đưa những trang bị chặn trong file robots.txt vào XML Sitemap.
Như vậy, qua bài viết này, Hướng Nghiệp Á Âu đã mang đến cho bạn thêm một góc nhìn mới về vấn đề deindex. Hi vọng bạn có thể tận dụng những kiến thức này để thúc đẩy hiệu quả cho hoạt động SEO hiện tại. Vậy những trang nào mà bạn sẽ deindex trước tiên? Hãy để lại ý kiến trong phần bình luận bên dưới nhé!






ĐƠN VỊ TUYỂN DỤNG CHEFJOB.VN
ĐẦU BẾP - BẾP BÁNH - PHA CHẾ - PHỤC VỤ - BUỒNG PHÒNG
LỄ TÂN - QUẢN LÝ NHÀ HÀNG - KHÁCH SẠN
Hotline: 1900 2175 - Web: www.chefjob.vn
SIÊU THỊ ĐVP MARKET
Chuyên bán sỉ lẻ Nguyên liệu - Dụng cụ - Máy móc
TRÀ SỮA - CAFÉ - QUÁN ĂN - QUÁN KEM - KINH DOANH BÁNH
Hotline: 028 7300 1770 - Web: www.dvpmarket.com
Có (0) bình luận cho: Deindex là gì? Cách deindex để tăng nhanh lượng truy cập tự nhiên (Phần 2)
Chưa có đánh giá nào.